Machine Learning Engineer Nanodegree¶
Deep Learning¶
📑 Practice Project 4: Convolutional Neural Networks
In your upcoming project, you will download pre-computed bottleneck features. In this notebook, we'll show you how to calculate VGG-16 bottleneck features on a toy dataset. Note that unless you have a powerful GPU, computing the bottleneck features takes a significant amount of time.
1. Load and Preprocess Sample Images¶
Before supplying an image to a pre-trained network in Keras, there are some required preprocessing steps. You will learn more about this in the project; for now, we have implemented this functionality for you in the first code cell of the notebook. We have imported a very small dataset of 8 images and stored the preprocessed image input as img_input. Note that the dimensionality of this array is (8, 224, 224, 3). In this case, each of the 8 images is a 3D tensor, with shape (224, 224, 3).
%%html
<style>
@import url('https://fonts.googleapis.com/css?family=Orbitron|Roboto');
body {background-color: #add8e6;}
a {color: darkblue; font-family: 'Roboto';}
h1 {color: steelblue; font-family: 'Orbitron'; text-shadow: 4px 4px 4px #aaa;}
h2, h3 {color: #483d8b; font-family: 'Orbitron'; text-shadow: 4px 4px 4px #aaa;}
h4 {color: slategray; font-family: 'Roboto';}
span {text-shadow: 4px 4px 4px #ccc;}
div.output_prompt, div.output_area pre {color: #483d8b;}
div.input_prompt, div.output_subarea {color: darkblue;}
div.output_stderr pre {background-color: #add8e6;}
div.output_stderr {background-color: #483d8b;}
</style>
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
import numpy as np
import glob
img_paths = glob.glob("images/*.jpg")
def path_to_tensor(img_path):
# loads RGB image as PIL.Image.Image type
img = image.load_img(img_path, target_size=(224, 224))
# convert PIL.Image.Image type to 3D tensor with shape (224, 224, 3)
x = image.img_to_array(img)
# convert 3D tensor to 4D tensor with shape (1, 224, 224, 3) and return 4D tensor
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
list_of_tensors = [path_to_tensor(img_path) for img_path in img_paths]
return np.vstack(list_of_tensors)
# calculate the image input. you will learn more about how this works the project!
img_input = preprocess_input(paths_to_tensor(img_paths))
print(img_input.shape)
2. Recap How to Import VGG-16¶
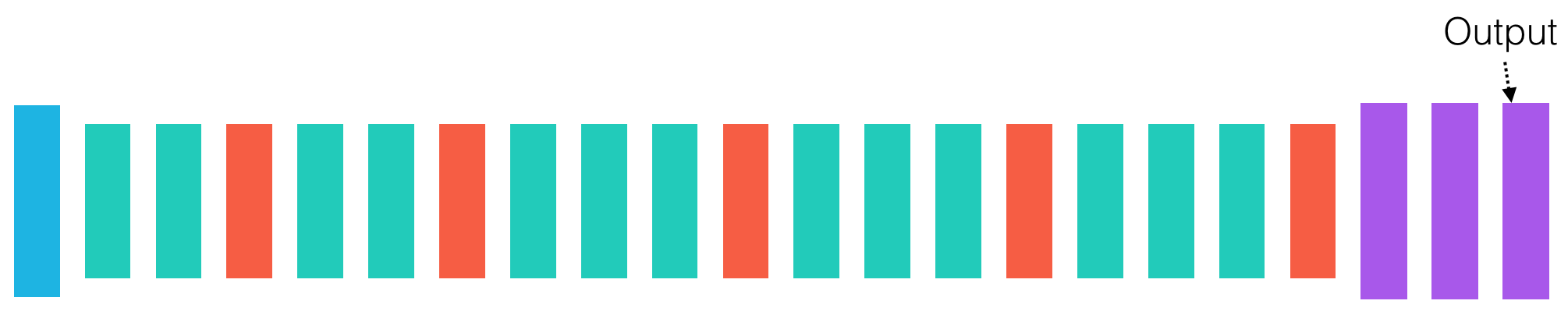
Recall how we import the VGG-16 network (including the final classification layer) that has been pre-trained on ImageNet.
from keras.applications.vgg16 import VGG16
model = VGG16()
model.summary()
For this network, model.predict returns a 1000-dimensional probability vector containing the predicted probability that an image returns each of the 1000 ImageNet categories. The dimensionality of the obtained output from passing img_input through the model is (8, 1000). The first value of 8 merely denotes that 8 images were passed through the network.
model.predict(img_input).shape
3. Import the VGG-16 Model, with the Final Fully-Connected Layers Removed¶
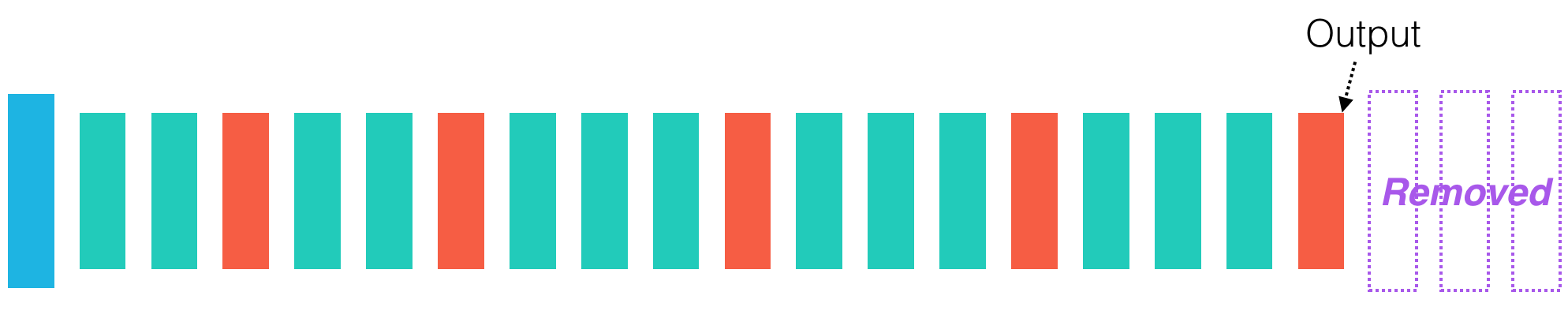
When performing transfer learning, we need to remove the final layers of the network, as they are too specific to the ImageNet database. This is accomplished in the code cell below.
from keras.applications.vgg16 import VGG16
model = VGG16(include_top=False)
model.summary()
4. Extract Output of Final Max Pooling Layer¶
Now, the network stored in model is a truncated version of the VGG-16 network, where the final three fully-connected layers have been removed. In this case, model.predict returns a 3D array (with dimensions $7\times 7\times 512$) corresponding to the final max pooling layer of VGG-16. The dimensionality of the obtained output from passing img_input through the model is (8, 7, 7, 512). The first value of 8 merely denotes that 8 images were passed through the network.
print(model.predict(img_input).shape)
This is exactly how we calculate the bottleneck features for your project!